

项目地址:
软件界面图片
🎙️ 当通义千问学会"开口说话":我与 Qwen3-TTS 的邂逅之旅
"文字是沉默的,但声音是有温度的。当 AI 开始理解声音背后的情感与个性,人机交互便跨越了一个维度。"
一、缘起:为什么需要一个"会说话"的 AI?
作为一个长期与代码为伴的开发者,我深知文字交流的局限。当我们开发语音助手、有声读物、或者为视障用户创建辅助工具时,冰冷的机械音总是让人感到疏离。
阿里云通义千问团队发布的 Qwen3-TTS 模型改变了这一切。这是一个基于离散多码本语言模型(Discrete Multi-codebook LM)架构的端到端语音合成系统,支持从文本直接生成高质量、富有情感的语音。
但官方仓库主要提供的是底层 API,对于普通用户来说门槛较高。于是,我决定为它穿上一件现代化的外衣——一个简洁优雅的 Gradio Web 界面。
二、项目架构:三位一体的语音合成引擎
我们的项目 Qwen3Audio 并非简单的"套壳",而是一个精心设计的三层架构系统:
┌─────────────────────────────────────────┐
│ Gradio Web UI │ ← 用户交互层
│ (app/ui.py - 318行精心打磨的界面) │
├─────────────────────────────────────────┤
│ TTS Engine │ ← 业务逻辑层
│ (app/tts_engine.py - 三种生成模式) │
├─────────────────────────────────────────┤
│ Model Manager │ ← 模型管理层
│ (app/model_manager.py - 自动下载/缓存) │
└─────────────────────────────────────────┘2.1 核心能力:三种"声线"模式
Qwen3-TTS 提供了三种截然不同的语音生成方式,就像一位百变的配音演员:
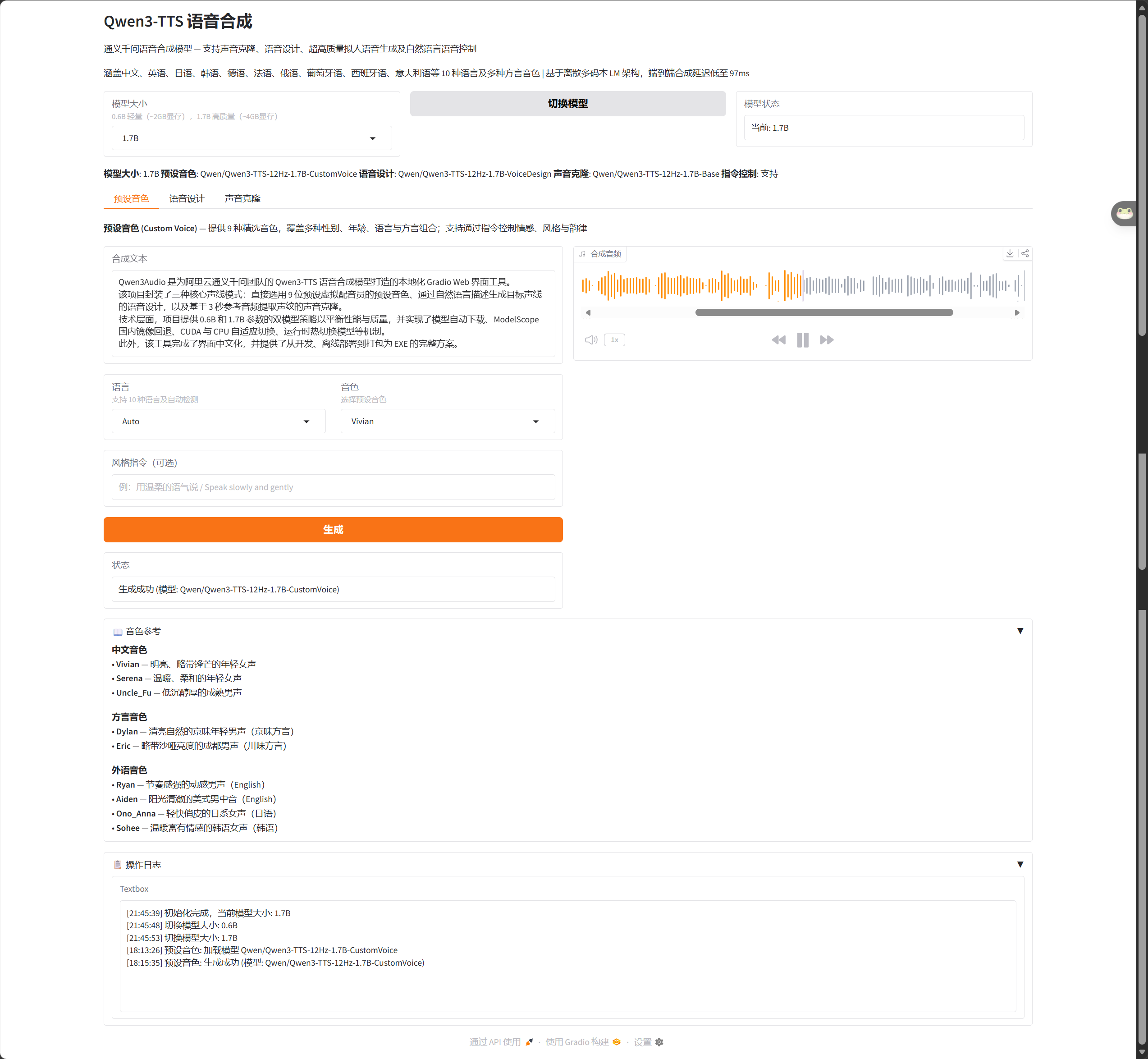
🎭 模式一:预设音色(Custom Voice)
这是"开箱即用"的模式。模型内置了 9 位精心调教的虚拟配音员:
💡 技术亮点:1.7B 模型支持指令控制!你可以告诉它:"用温柔的语气说"或"Speak slowly and gently",它会调整韵律和情感表达。
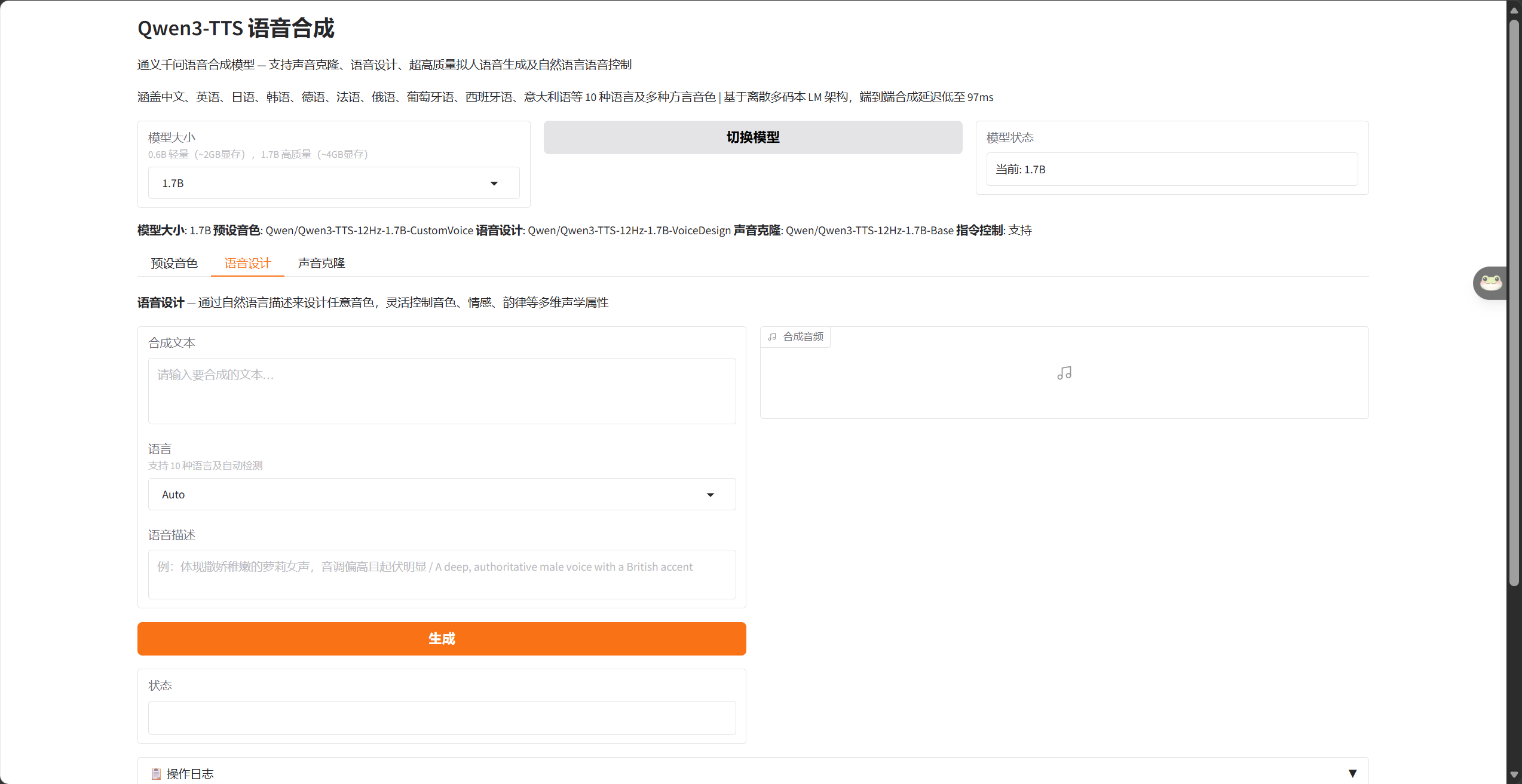
🎨 模式二:语音设计(Voice Design)
这是我最钟爱的功能。不再受限于预设音色,你可以用自然语言描述任何你想要的声线:
# 示例描述
"A deep, authoritative male voice with a British accent"
"体现撒娇稚嫩的萝莉女声,音调偏高且起伏明显"模型会将这段描述转化为声学特征,生成完全自定义的音色。这就像拥有了一位能听懂人话的调音师。
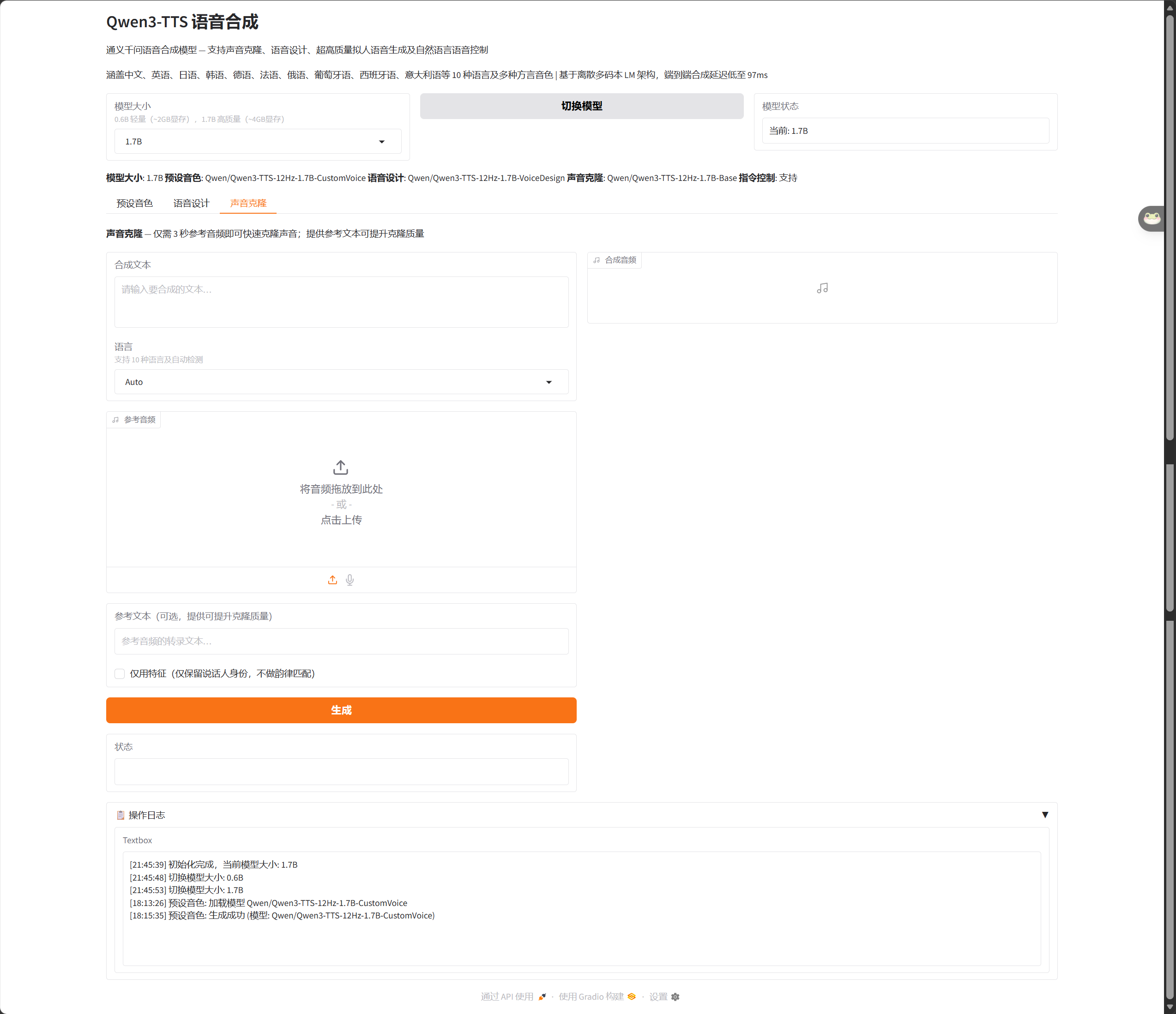
🎤 模式三:声音克隆(Voice Clone)
只需 3 秒参考音频,模型就能提取说话人的声纹特征,然后用这个"声音面具"朗读任意文本。
技术实现上,这依赖于 x-vector 声纹编码技术。你可以选择:
完整模式:保留韵律和说话风格
仅特征模式:只保留说话人身份,使用标准韵律(更快)
三、技术实现:那些"魔鬼细节"
3.1 双模型策略:轻量与质量的权衡
Qwen3-TTS 提供了两个版本:
我们的 UI 支持运行时热切换模型大小,无需重启服务。这得益于 TTSEngine.set_model_size() 方法的实现:
def set_model_size(self, model_size: str) -> None:
if model_size == self.model_size:
return
# 先卸载当前模型释放显存
self.model_manager.unload_model()
self.model_manager.model_size = model_size
self.model_size = model_size3.2 智能模型管理:自动下载与缓存
模型文件托管在 HuggingFace,首次使用时会自动下载到 ~/.cache/qwen3-tts/。为了照顾国内用户,我们还实现了 ModelScope 镜像回退:
try:
# 优先从 HuggingFace 下载
downloaded_path = snapshot_download(repo_id=model_id, ...)
except Exception as e:
# 失败时自动尝试国内镜像
from modelscope import snapshot_download as ms_snapshot_download
downloaded_path = ms_snapshot_download(model_id=model_id, ...)ModelScope回退需要安装有对应的
pip install modelscope3.3 设备自适应:CUDA 与 CPU 的无缝切换
PS:似乎CPU运行无效,PyTorch CPU版本会报错。
考虑到用户的硬件差异,我们实现了自动降级机制:PyTorch
def ensure_device_available(config: AppConfig) -> AppConfig:
if not torch.cuda.is_available():
print("WARNING: CUDA is not available! Falling back to CPU...")
config.device = "cpu"
return config当检测到 CUDA 不可用时,系统会友好地提示用户安装 CUDA 版本的 PyTorch,而不是直接崩溃。
四、UI 设计:少即是多
Gradio 是一个优秀的 ML Demo 框架,但默认的组件往往显得"过于技术"。我们对界面进行了完全中文化和视觉优化:
4.1 三标签页布局
┌────────────────────────────────────────┐
│ [预设音色] [语音设计] [声音克隆] │
├────────────────────────────────────────┤
│ │
│ 根据当前选择的模型大小动态显示/隐藏 │
│ 语音设计标签页(仅 1.7B 支持) │
│ │
└────────────────────────────────────────┘4.2 实时状态反馈
界面底部集成了操作日志面板,让用户清楚知道:
模型何时开始加载
当前使用哪个模型
生成是否成功
4.3 模型信息面板
实时显示当前模型的能力矩阵:
是否支持指令控制
是否支持语音设计
各模型的 HuggingFace ID
五、部署方案:从开发到生产
5.1 开发模式
# 一键启动
python main.py
# 预加载特定模型(减少首次使用等待)
python main.py --mode custom_voice --model-size 1.7B5.2 离线部署
对于无网络环境(如内网服务器),我们提供了完整的离线方案:
# 步骤1:在有网络的环境下下载模型
python download_models.py --for-exe
# 步骤2:复制到离线机器
# 模型位置: ~/.cache/qwen3-tts/
# 步骤3:离线启动
python main.py --offline --mode all5.3 打包为 EXE
使用 PyInstaller 可以将整个应用打包为独立可执行文件:
build_exe.bat # Windows
./build_exe.sh # Linux/Mac输出约 10-15GB(含模型),可在无 Python 环境的机器上直接运行。解决了部分必须完全在离线场景使用的问题。
六、技术亮点回顾
七、写在最后
这个项目的开发过程让我深刻体会到:好的工具应该像空气一样自然存在。
当用户打开浏览器,输入文字,点击"生成",然后听到一段富有情感的语音时——他们不需要知道背后有 17 亿参数的神经网络在运转,不需要关心 CUDA 版本是否匹配,不需要理解什么是 x-vector 或离散码本。
他们只需要知道:这个 AI,真的会说话。
项目地址: https://github.com/RSJWY/Qwen3Audio
模型来源: Qwen3-TTS by 阿里云通义千问团队
如果你也对这个项目感兴趣,欢迎 Star、Fork、提 Issue。让我们一起,让 AI 的声音更有温度。 🎙️✨
Qwen3-TTS本地生成工具
https://blog.rsjwy.com/archives/qwen3-audio
评论